|
XOOPS API 2.5.11 Beta1
UI v0.5
Réalisé par monxoops.fr
|
|
XOOPS API 2.5.11 Beta1
UI v0.5
Réalisé par monxoops.fr
|
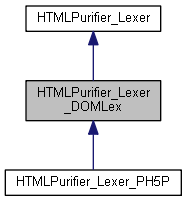
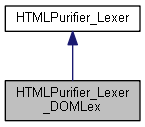
 Graphe d'héritage de HTMLPurifier_Lexer_DOMLex: Graphe de collaboration de HTMLPurifier_Lexer_DOMLex:
Graphe d'héritage de HTMLPurifier_Lexer_DOMLex: Graphe de collaboration de HTMLPurifier_Lexer_DOMLex:Fonctions membres publiques | |
| __construct () | |
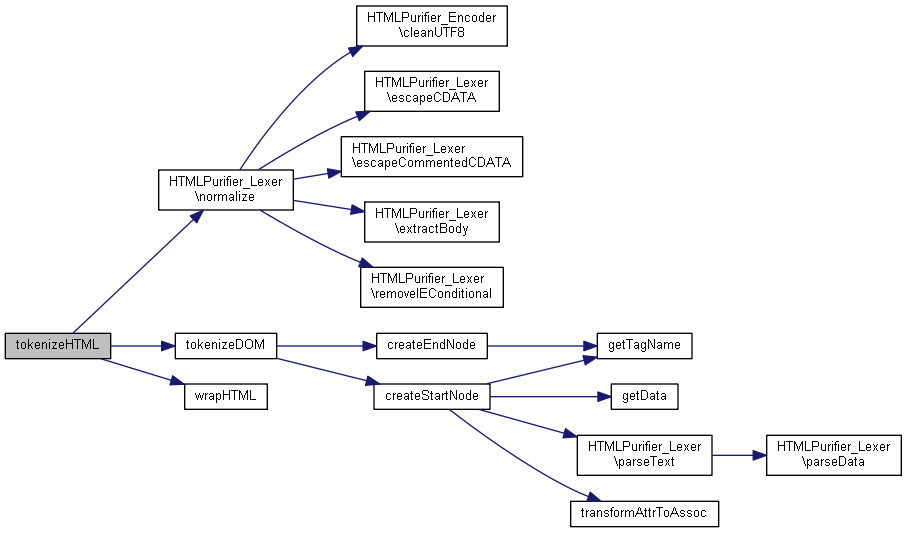
| tokenizeHTML ($html, $config, $context) | |
| muteErrorHandler ($errno, $errstr) | |
| callbackUndoCommentSubst ($matches) | |
| callbackArmorCommentEntities ($matches) | |
| Fonctions membres publiques hérités de HTMLPurifier_Lexer | |
| parseText ($string, $config) | |
| parseAttr ($string, $config) | |
| parseData ($string, $is_attr, $config) | |
| normalize ($html, $config, $context) | |
| extractBody ($html) | |
Fonctions membres protégées | |
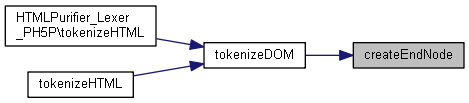
| tokenizeDOM ($node, &$tokens, $config) | |
| getTagName ($node) | |
| getData ($node) | |
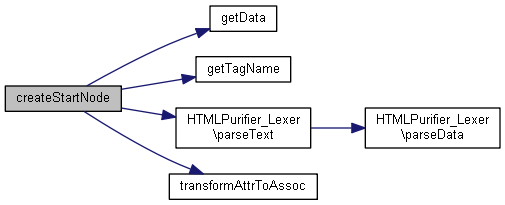
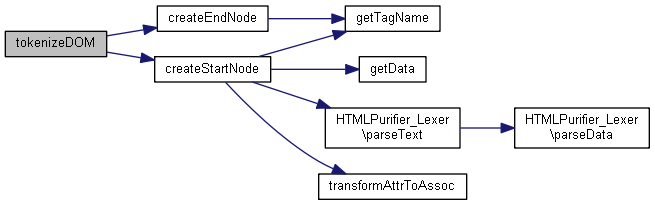
| createStartNode ($node, &$tokens, $collect, $config) | |
| createEndNode ($node, &$tokens) | |
| transformAttrToAssoc ($node_map) | |
| wrapHTML ($html, $config, $context, $use_div=true) | |
Attributs privés | |
| $factory | |
Membres hérités additionnels | |
| Fonctions membres publiques statiques hérités de HTMLPurifier_Lexer | |
| static | create ($config) |
| Champs de données hérités de HTMLPurifier_Lexer | |
| $tracksLineNumbers = false | |
| Fonctions membres protégées statiques hérités de HTMLPurifier_Lexer | |
| static | escapeCDATA ($string) |
| static | escapeCommentedCDATA ($string) |
| static | removeIEConditional ($string) |
| static | CDATACallback ($matches) |
| Attributs protégés hérités de HTMLPurifier_Lexer | |
| $_special_entity2str | |
Parser that uses PHP 5's DOM extension (part of the core).
In PHP 5, the DOM XML extension was revamped into DOM and added to the core. It gives us a forgiving HTML parser, which we use to transform the HTML into a DOM, and then into the tokens. It is blazingly fast (for large documents, it performs twenty times faster than HTMLPurifier_Lexer_DirectLex,and is the default choice for PHP 5.
| __construct | ( | ) |
Réimplémentée à partir de HTMLPurifier_Lexer.
| callbackArmorCommentEntities | ( | $matches | ) |
Callback function that entity-izes ampersands in comments so that callbackUndoCommentSubst doesn't clobber them
| array | $matches |
| callbackUndoCommentSubst | ( | $matches | ) |
Callback function for undoing escaping of stray angled brackets in comments
| array | $matches |
|
protected |
| DOMNode | $node | |
| HTMLPurifier_Token[] | $tokens |
Voici le graphe d'appel pour cette fonction : Voici le graphe des appelants de cette fonction :
|
protected |
| DOMNode | $node | DOMNode to be tokenized. |
| HTMLPurifier_Token[] | $tokens | Array-list of already tokenized tokens. |
| bool | $collect | Says whether or start and close are collected, set to false at first recursion because it's the implicit DIV tag you're dealing with. |
Voici le graphe d'appel pour cette fonction : Voici le graphe des appelants de cette fonction :
|
protected |
Portably retrieve the data of a node; deals with older versions of libxml like 2.7.6
| DOMNode | $node |
Voici le graphe des appelants de cette fonction :
|
protected |
Portably retrieve the tag name of a node; deals with older versions of libxml like 2.7.6
| DOMNode | $node |
Voici le graphe des appelants de cette fonction :| muteErrorHandler | ( | $errno, | |
| $errstr | |||
| ) |
An error handler that mutes all errors
| int | $errno | |
| string | $errstr |
|
protected |
Iterative function that tokenizes a node, putting it into an accumulator. To iterate is human, to recurse divine - L. Peter Deutsch
| DOMNode | $node | DOMNode to be tokenized. |
| HTMLPurifier_Token[] | $tokens | Array-list of already tokenized tokens. |
Voici le graphe d'appel pour cette fonction : Voici le graphe des appelants de cette fonction :| tokenizeHTML | ( | $html, | |
| $config, | |||
| $context | |||
| ) |
| string | $html | |
| HTMLPurifier_Config | $config | |
| HTMLPurifier_Context | $context |
Réimplémentée à partir de HTMLPurifier_Lexer.
Réimplémentée dans HTMLPurifier_Lexer_PH5P.
Voici le graphe d'appel pour cette fonction :
|
protected |
Converts a DOMNamedNodeMap of DOMAttr objects into an assoc array.
| DOMNamedNodeMap | $node_map | DOMNamedNodeMap of DOMAttr objects. |
Voici le graphe des appelants de cette fonction :
|
protected |
Wraps an HTML fragment in the necessary HTML
| string | $html | |
| HTMLPurifier_Config | $config | |
| HTMLPurifier_Context | $context |
Voici le graphe des appelants de cette fonction :
|
private |
 1.8.17
1.8.17